Background
- Marking every start and end times of every actions instance is very expensive and hard to acquire, but action recognition needs more and more large datasets to improve the performance.
- Weak video-level supervision has been successfully exploited for recognition in untrimmed videos, however it's challenged when the number of different action instances in videos increases.
Motivation
The idea, single timestamp supervision, is inspired by similar approaches for single point annotations in image based semantic segmentation. It is a compromise between cost and performance. Furthermore, these single timestamps can even be collected from audio narrations and video subtitles.
Methods & Framework
1. Sampling Near the Timestamps: The Plateau Function
This paper has proposed the following plateau function to model the probability density of the sampling distributiolns:
$$
g(x|c, w, s) = \frac{1}{
(e^{s(x-c-w)}+1)
(e^{s(-x+c-w)}+1)
}
$$
Each timestamps will have its' initial plateau function instance respectively, with \(c^v_i=a^v_i\), \(w=45\) and \(s=0.75\). Then, let's define the notations first:
- \(a^v_i\): the \(i\)-th single timestamp in an untrimmed video \(v\)
- \(y^v_i\): the corresponding class label
- \(beta^v_i=(c^v_i, w^v_i, s^v_i)\), where \(c^v_i=a^v_i\): the parameters of a plateau function instance
- \(G(beta^v_i)\): the corresponding plateau function instance
- \(t\): the index of frames list \(\mathcal{F}^k\)
which s.t. \(i\in{1..N_v}\) and \(v\in{1..M}\)
And let:
$$
\mathcal{F}^k=(
x gets G(\beta^v_i)
, : ,
y^v_i=k,\forall i\in{1..N_v},
\forall v\in{1..M}
)
$$
$$
s.t.,,P(k|\mathcal{F}^k_{t-1})\ge P(k|\mathcal{F}^k_t)
$$
be the list of sampled frames with corresponding class \(k\). Then the top-\(T\) frames within it would be fed into training process, where \(T=h,|mathcal{F}^k|, hin[0, 1]\). The \(h\) would increase slowly when learning the model.
2. Updating the Distribution Function
The initial sampling functions are not precise enough in most of times, so we need a policy to update it. It contains three steps (this note would be too long if I cover it in detail...)
2.1 Finding Update proposals
We denote each update proposal with \(\gamma^v_j=(c^v_j, w^v_j, s^v_j)\). The set of update proposals for \(\beta^v_i\) is thus:
$$
\mathcal{Q}^v_i={\gamma^vj,:,c^v{i-1}<c^vi<c^v{i+1}}
$$
2.2 Selecting the Update Proposals
First, select the frames such that \(g(x|\beta^v_i)>0.5\), and denote it with \(\mathcal{X}\). Then we can select the proposal \(\widehat{\gamma^v_i}\) with highest confidence for each \(\beta^v_i\):
$$
\widehat{\gamma^vi}=\text{\arg min}{\gamma^v_j}(\rho(\gamma^v_j)-\rho(\beta^v_j))
$$
where \(\rho(\beta^vi)=\frac1{|\mathcal{X}|}\sum{x\in\mathcal{X}}P(y^v_i|x)\).
2.3 Updating Proposals
Nothing special. Every parameters could have its own update rate.
Experiments
Datasets: THUMOS 14, BEOID, EPIC Kitchens.
Architecture: BN-Inception, pretrained on Kinetics, embeded in framework TSN.
Evaluation metrics: Top-1 accuracy.
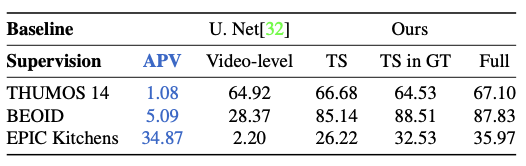
Where:
APVmeans the average of unique Actions Per training Video.Video-levelmeans video-level supervision (contains or not contains)TSmeans \(a_i \sim U[\sigma_i-1sec, \epsilon_i+1sec]\)TS in GTmeans \(a_i \sim N(\frac{\sigma_i+\epsilon_i}2, 1sec)\)Fullmeans giving the exact extent of every action instance to the model.
Pros. & Cons.
Pros: Much easier to do the annotation, which makes the larger datasets possible.
Cons: In the real-world application, no timestamps can be supplied.
Comments
- What if alleviate the supervision more radically: only with the number of action instances provided, and let the sampling function learn where to go by itself?
- It seems that the refinement process of action boundaries is applicable in many traditional models / frameworks.
- There are too much plateau function instances! What if every action class shares a common instance?